
Athena で データが 0 件となり読み込めない原因が Partition Projection の range に指定した時間の時差が原因だった

コーヒーが好きな emi です。
S3 に格納した CSV ファイルを Athena の Partition Projection(パーティション射影)で動的に読み込もうとしたところ、うまく読み込めず「結果 0 件」となってしまいました。エラーにはならないのにおかしいな?と思い調査したところ、原因は「時差」でした。事象と解決方法を以下に記載します。
うまくいかない事象の説明
以下のような CSV ファイルを格納しています。
datetime,department,section,status,chocolate,donut,osenbei
2024-10-16 17:00:00.000,コンピューティング部,EC2課,不調,19,1,20
2024-10-16 17:00:00.000,コンピューティング部,Lambda課,不調,12,4,22
2024-10-16 17:00:00.000,コンピューティング部,Lightsail課,不調,13,3,24
2024-10-16 17:00:00.000,ストレージ部,EFS課,超ごきげん,18,7,29
2024-10-16 17:00:00.000,ストレージ部,FSx課,ごきげん,18,1,24
2024-10-16 17:00:00.000,ストレージ部,S3課,不調,15,2,20
2024-10-16 17:00:00.000,データベース部,RDS課,普通,14,2,28
2024-10-16 17:00:00.000,データベース部,DocumentDB課,不調,19,7,29
2024-10-16 17:00:00.000,データベース部,DynamoDB課,超ごきげん,11,2,24
CSV ファイルを格納している S3 のパス(S3 URI)は以下です。
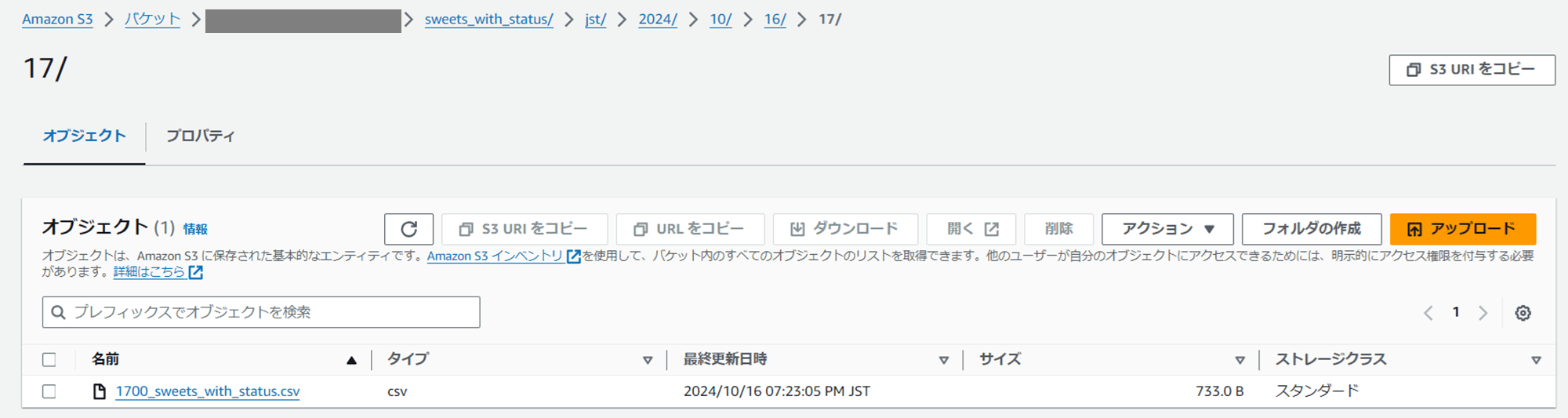
s3://<S3 バケット名>/sweets_with_status/jst/2024/10/16/17/1700_sweets_with_status.csv
あらかじめ Athena で以下のクエリを実行し spiceincrementalupdatedb というデータベースを作成しておきます。
CREATE DATABASE IF NOT EXISTS SPICEINCREMENTALUPDATEDB;
Athena では以下のように sweets_with_status テーブルを作成しました。パーティションキーを partition_date としています。
CREATE EXTERNAL TABLE IF NOT EXISTS `spiceincrementalupdatedb`.`sweets_with_status` (
`datetime` string,
`department` string,
`section` string,
`status` string,
`chocolate` int,
`donut` int,
`osenbei` int
)
PARTITIONED BY (
`partition_date` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim' = ',',
'skip.header.line.count' = '1'
)
LOCATION 's3://<S3 バケット名>/sweets_with_status/jst/'
TBLPROPERTIES (
'classification' = 'csv',
'projection.enabled' = 'true',
'projection.partition_date.type' = 'date',
'projection.partition_date.format' = 'yyyy/MM/dd/HH',
'projection.partition_date.range' = '2024/10/15/00,NOW',
'projection.partition_date.interval' = '1',
'projection.partition_date.interval.unit' = 'HOURS',
'storage.location.template' = 's3://<S3 バケット名>/sweets_with_status/jst/${partition_date}'
);
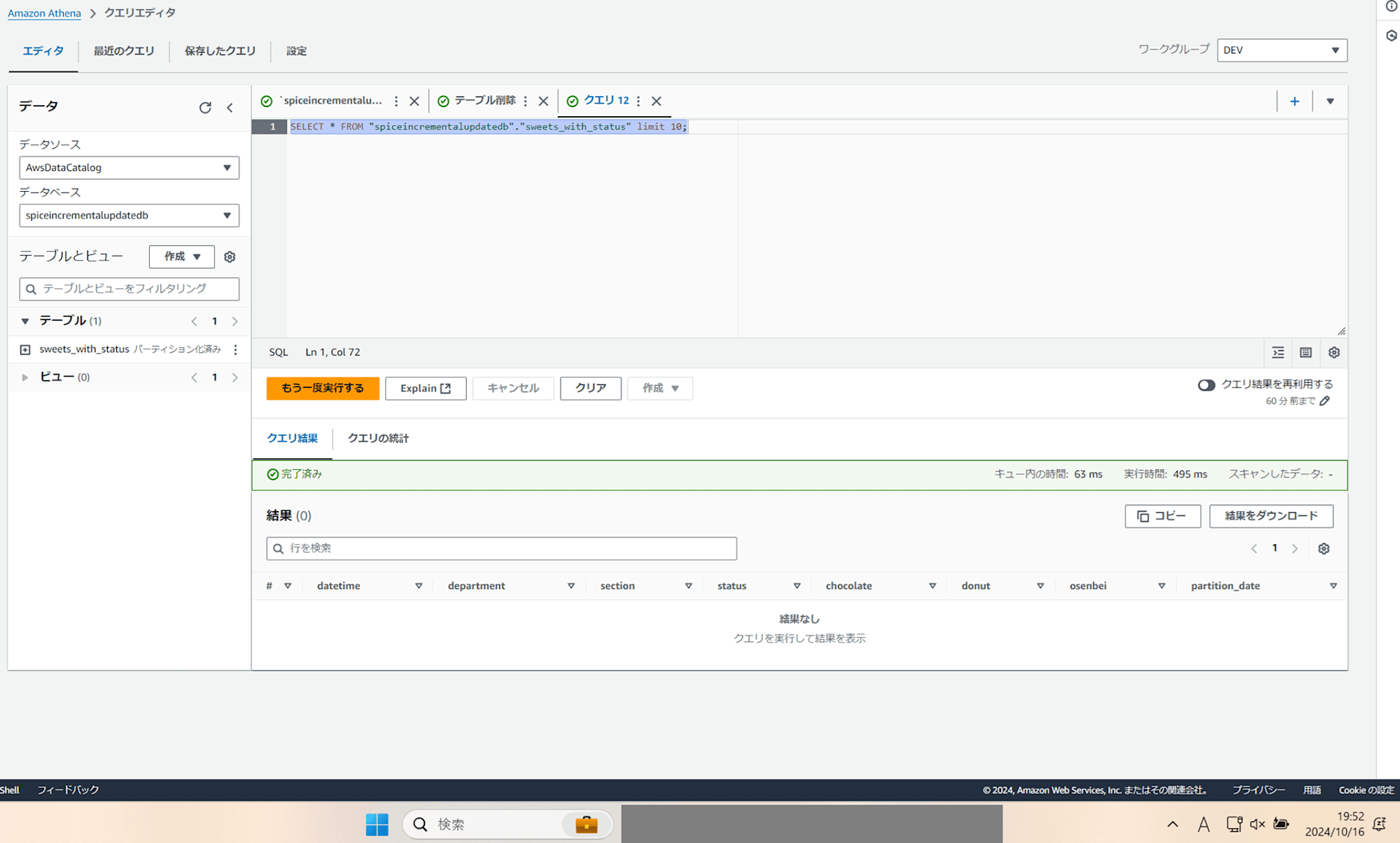
作成したテーブルは画面左に表示されています。作成したテーブル名の右の三点リーダをクリックすると「テーブルをプレビュー」という表示があるのでクリックすると、以下のように最初の 10 行を表示するクエリが生成され実行されます。
SELECT * FROM "spiceincrementalupdatedb"."sweets_with_status" limit 10;
しかし、結果 0 件となってしまいました。この時、検証をしていた時間は日本時間で 2024/10/16 (水) 19:30~19:52 くらいでした。
projection.columnName.range の NOW が意味する時刻
ドキュメントの 日付型 を確認すると、日付列は UTC として生成されると記載されています。
射影される日付列は、クエリの実行時に協定世界時 (UTC) で生成されます。
パーティション射影用にサポートされている型 - Amazon Athena 日付型
今回パーティション化されたデータの「開始日」と「終了日」を projection.partition_date.range で定義しており、最新のデータを取得する意図で終了日を NOW としました。
しかし、NOW の解釈は UTC なので、実行した時間を考慮すると…
| 検証していた時間 | 2024/10/16 19:52 |
CSV ファイルを格納した S3 パスの時刻部分(partition_date) |
2024/10/16/17(yyyy/MM/dd/HH) |
UTC で解釈した NOW |
2024/10/16 10:52 |
つまり、Athena 側で NOW は 2024/10/16 10:52 と解釈されており、検証をしていた時間や S3 に格納したファイルの時間は未来になっていたのです。

projection.columnName.range の時刻を変更
一旦テーブルを削除し、
DROP TABLE `sweets_with_status`;
以下のクエリでテーブルを再作成します。パーティション化されたデータの「終了日」を NOW ではなく 2024/10/20/00 と未来の時間にしました。
CREATE EXTERNAL TABLE IF NOT EXISTS `spiceincrementalupdatedb`.`sweets_with_status` (
`datetime` string,
`department` string,
`section` string,
`status` string,
`chocolate` int,
`donut` int,
`osenbei` int
)
PARTITIONED BY (
`partition_date` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim' = ',',
'skip.header.line.count' = '1'
)
LOCATION 's3://<S3 バケット名>/sweets_with_status/jst/'
TBLPROPERTIES (
'classification' = 'csv',
'projection.enabled' = 'true',
'projection.partition_date.type' = 'date',
'projection.partition_date.format' = 'yyyy/MM/dd/HH',
'projection.partition_date.range' = '2024/10/15/00,2024/10/20/00',
'projection.partition_date.interval' = '1',
'projection.partition_date.interval.unit' = 'HOURS',
'storage.location.template' = 's3://<S3 バケット名>/sweets_with_status/jst/${partition_date}'
);
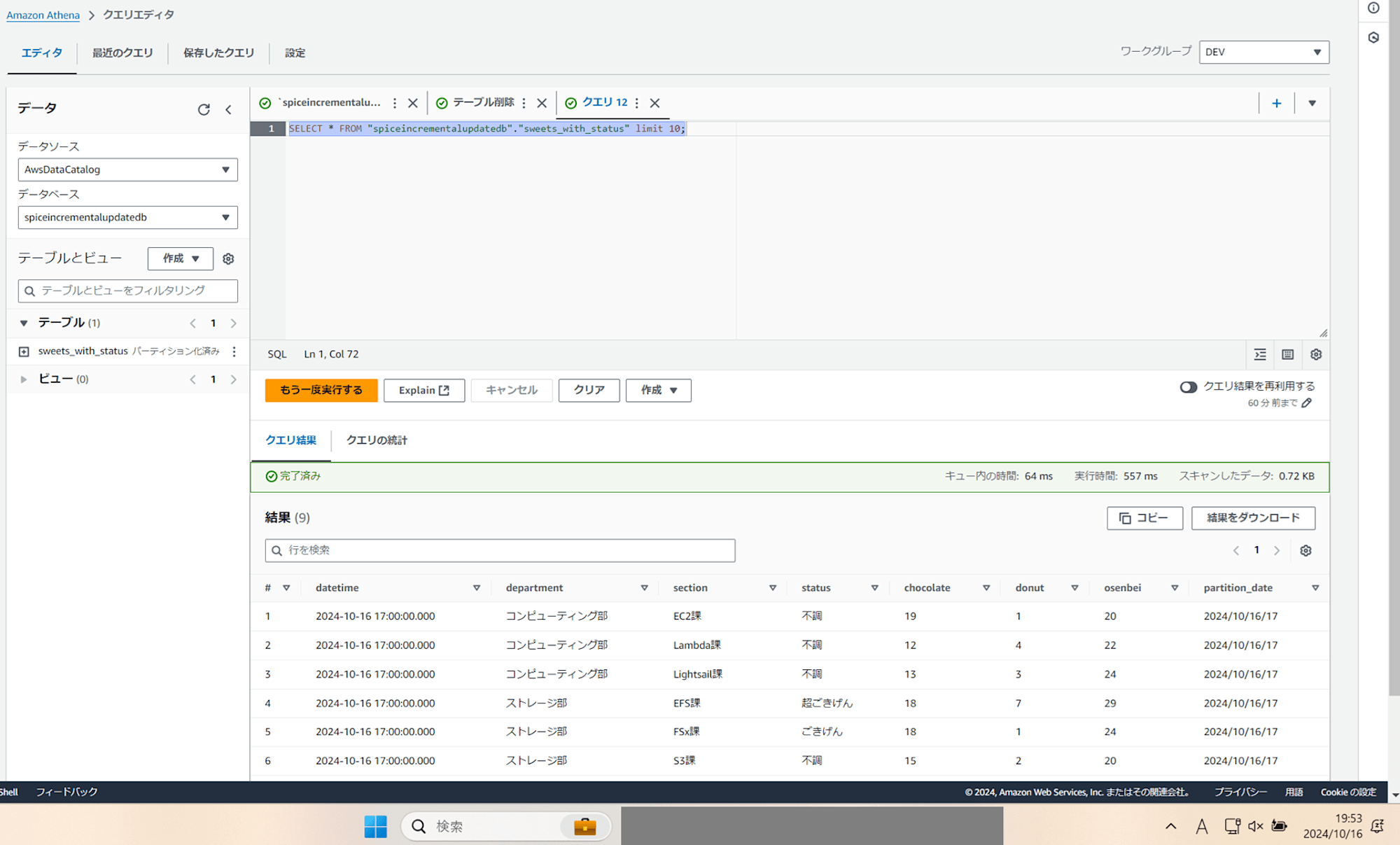
テーブルをプレビューすると、データが表示されました!
NOW は相対時間も設定可能
ドキュメントの 日付型 を確認すると、パーティション化されたデータの「開始日」と「終了日」には相対時間も設定できると記載されています。
この列には、次の正規表現パターンの形式で相対日付文字列を含めることもできます。
\s*NOW\s*(([\+\-])\s*([0-9]+)\s*(YEARS?|MONTHS?|WEEKS?|DAYS?|HOURS?|MINUTES?|SECONDS?)\s*)?
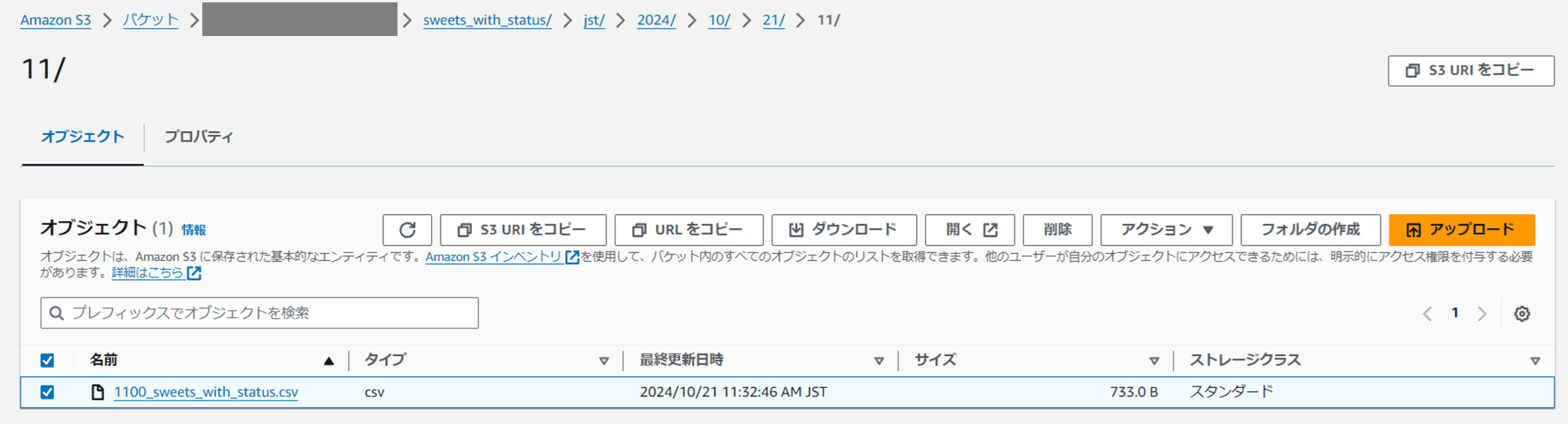
こちらも試してみます。CSV ファイルを現在の時間で配置し直します。データの時刻は 2024/10/21 11:00 としています。
s3://<S3 バケット名>/sweets_with_status/jst/2024/10/21/11/1100_sweets_with_status.csv
検証時刻は日本時間で 2024/10/21 (月) 11:40 くらいでした。
まず以下のクエリで sweets_with_status_2 テーブルを作成します。パーティション化されたデータの「終了日」は NOW としています。つまり、「終了日」は UTC 時間で解釈された時間 2024/10/21 02:40 くらいとなるはずです。
CREATE EXTERNAL TABLE IF NOT EXISTS `spiceincrementalupdatedb`.`sweets_with_status_2` (
`datetime` string,
`department` string,
`section` string,
`status` string,
`chocolate` int,
`donut` int,
`osenbei` int
)
PARTITIONED BY (
`partition_date` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim' = ',',
'skip.header.line.count' = '1'
)
LOCATION 's3://<S3 バケット名>/sweets_with_status/jst/'
TBLPROPERTIES (
'classification' = 'csv',
'projection.enabled' = 'true',
'projection.partition_date.type' = 'date',
'projection.partition_date.format' = 'yyyy/MM/dd/HH',
'projection.partition_date.range' = '2024/10/20/00,NOW',
'projection.partition_date.interval' = '1',
'projection.partition_date.interval.unit' = 'HOURS',
'storage.location.template' = 's3://<S3 バケット名>/sweets_with_status/jst/${partition_date}'
);
「テーブルをプレビュー」で確認すると、結果 0 件となります。想定通りです。検証をしていた時間は日本時間で 2024/10/21 (月) 11:45 くらいでした。
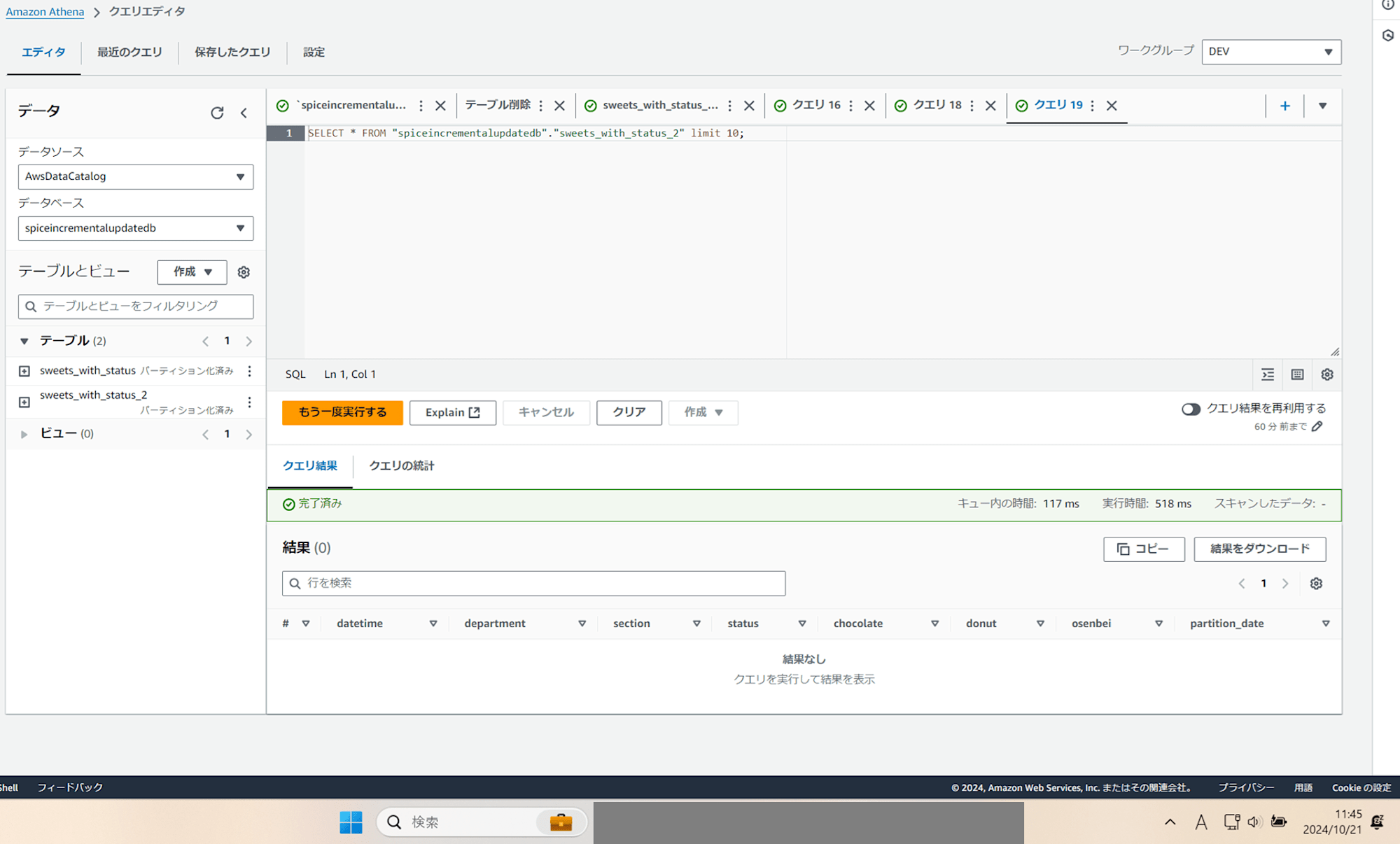
一旦テーブルを削除し、
DROP TABLE `sweets_with_status_2`;
以下のクエリでテーブルを再作成します。今度はパーティション化されたデータの「終了日」を NOW ではなく NOW+9HOURS と、日本時間として解釈するようにしました。
CREATE EXTERNAL TABLE IF NOT EXISTS `spiceincrementalupdatedb`.`sweets_with_status_2` (
`datetime` string,
`department` string,
`section` string,
`status` string,
`chocolate` int,
`donut` int,
`osenbei` int
)
PARTITIONED BY (
`partition_date` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim' = ',',
'skip.header.line.count' = '1'
)
LOCATION 's3://<S3 バケット名>/sweets_with_status/jst/'
TBLPROPERTIES (
'classification' = 'csv',
'projection.enabled' = 'true',
'projection.partition_date.type' = 'date',
'projection.partition_date.format' = 'yyyy/MM/dd/HH',
'projection.partition_date.range' = '2024/10/20/00,NOW+9HOURS',
'projection.partition_date.interval' = '1',
'projection.partition_date.interval.unit' = 'HOURS',
'storage.location.template' = 's3://<S3 バケット名>/sweets_with_status/jst/${partition_date}'
);
「テーブルをプレビュー」で確認すると、データが確認できました!
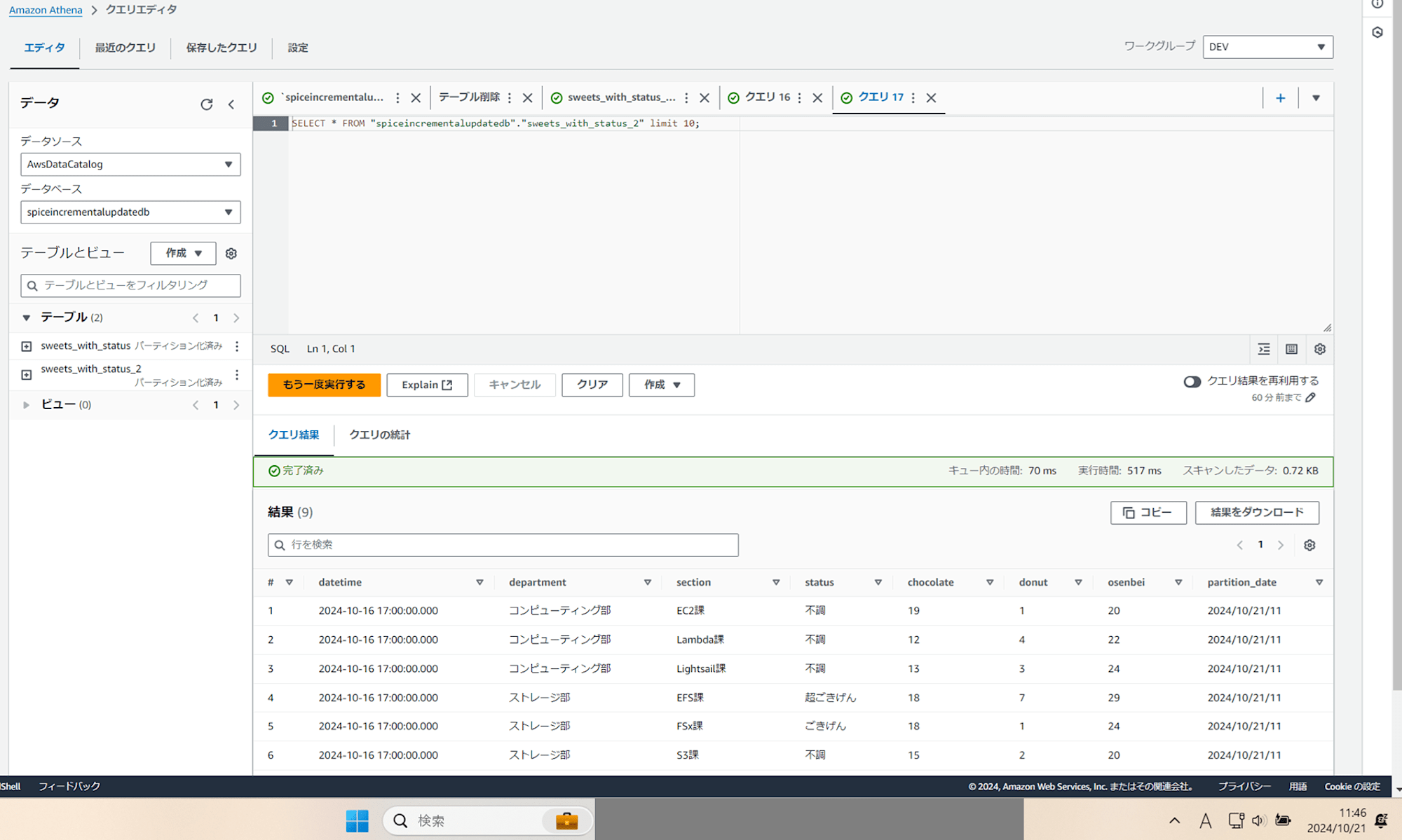
終わりに
カラムの設定などは間違っていないはずなのにデータが読み込めず、苦戦しました。Athena を日本で使う場合は「Athena にとって今は何時だろう?」と Athena の気持ちになってみると良いかもしれません。
参考






